
Maurizio Carpita – Università degli Studi di Brescia
maurizio.carpita@unibs.it
A seguito dell’approvazione nel 2014 del Piano Straordinario di legislatura per l’apprendimento delle lingue comunitarie – Trentino Trilingue, nell’estate del 2015 la Giunta della Provincia Autonoma di Trento ha avviato un programma di verifica pluriennale dei livelli di competenza nelle lingue inglese e tedesco degli studenti trentini frequentanti la scuola dell’obbligo, affidandone la realizzazione a IPRASE (Istituto Provinciale per la Ricerca e la Sperimentazione Educativa; www.iprase.tn.it). Considerato il numero crescente di iniziative di valutazione e di certificazione messe in atto direttamente dalle singole scuole, il crescente impiego delle prove standardizzate a livello nazionale (INVALSI) e internazionale (PISA, TIMSS, PIRLS) riferite ad altre discipline (lingua italiana, matematica, scienze) e quanto previsto dalla Commissione Europea con il CEFR per le lingue (Common European Framework of Reference for Languages), il programma di verifica definito da IPRASE si è concretizzato con la progettazione e l’avvio del Trentino Language Testing (TLT), un’azione sistematica a livello provinciale di valutazione del profilo linguistico degli studenti dei diversi ordini e gradi di scuola.
La prima rilevazione delle competenze linguistiche svolta con il TLT di IPRASE è stata realizzata nell’aprile 2016 e ha coinvolto un campione di 3.000 studenti tra i 10 e i 15 anni, frequentanti l’ultimo anno della scuola primaria e della scuola secondaria di primo grado, il secondo anno delle secondarie di secondo grado insieme al terzo anno dell’istruzione e formazione professionale. Ne è seguita la realizzazione con le medesime modalità di una seconda rilevazione, che nel corso della primavera 2018 ha coinvolto altri 2.500 studenti (i due rapporti delle due rilevazioni TLT sono scaricabili dal sito di IPRASE: www.iprase.tn.it/pubblicazioni-dettaglio/).
In entrambe le occasioni del TLT 2016 e 2018, esperti linguistici insieme a un team di docenti dei tre ordini e gradi scolastici considerati hanno predisposto tre diversi test standardizzati nella doppia versione inglese e tedesco, con obiettivo di verificare quattro competenze linguistiche (ascolto, lettura, scrittura e parlato) rispettivamente per i livelli A1, A2 e B1. La statistica è stata utilizzata ampiamente utilizzata dal TLT, in particolare per la definizione del disegno campionario e per la verifica delle caratteristiche psicometriche dei test linguistici (si veda per approfondimenti Carpita et al., 2018).
Per quanto riguarda il campionamento, è stato adottato lo schema del campione probabilistico a due stadi: al primo stadio sono state estratte le scuole e al secondo stadio le classi; tutti gli studenti delle classi estratte sono entrati a far parte del campione. Inoltre, per i primi due livelli di formazione considerata è stata utilizzata anche la stratificazione implicita ordinando le scuole per territorio e dimensione complessiva, mentre per il livello di istruzione superiore è stata utilizzata la stratificazione esplicita per indirizzi di studio.
La verifica delle caratteristiche psicometriche dei test linguistici TLT è stata effettuata analizzando le risposte del campione di studenti per le competenze ascolto e lettura (ogni domanda prevedeva 4 alternative di risposta) con il Modello di Rasch: questo modello permette di stimare contemporaneamente le abilità linguistica degli studenti e le difficoltà delle domande del test considerando solamente se le risposte date sono giuste oppure sbagliate.
A titolo di esempio delle analisi effettuate, nella Figura 1 sono rappresentati i risultati ottenuti nel caso del Test B1 di Inglese per l’abilità lettura del TLT 2018. Il grafico a sinistra riporta la mappa Studenti-Domande ottenuta con il modello di Rasch: i quesiti sono ordinati dal più facile (a sinistra) al più difficile (a destra) e gli studenti sono ordinati dal meno abile (a sinistra) ai più abili (a destra). La linea rossa verticale rappresenta la soglia che è stata considerata per definire il raggiungimento del livello di competenza linguistica previsto dal test (in questo caso B1).
Figura 1. Analisi Statistica del Test B1 – Inglese lettura (TLT 2018)
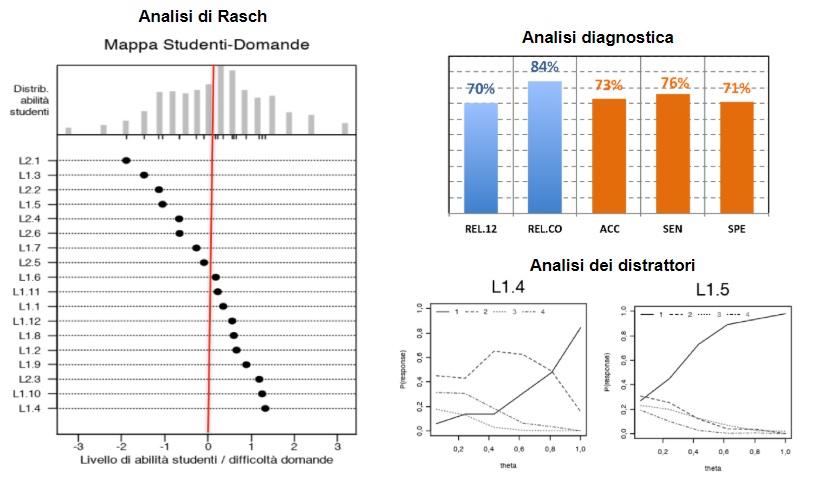
Si mostrano infine due esempi di analisi dei distrattori, ovvero delle risposte alternative inserite nella domanda insieme alla risposta esatta: se le risposte sono ben formulate ci si attende che all’aumentare dell’abilità degli studenti le probabilità dei distrattori siano sempre basse e tendenzialmente decrescenti, mentre la probabilità per la risposta corretta (indicata con la linea continua) dovrebbe essere chiaramente crescente. Si osserva che per la domanda L1.4 è presente un distrattore con probabilità stimata di risposta troppo alta anche per abilità stimate elevate, mentre il comportamento delle probabilità stimante delle risposte per la domanda L1.5 è conforme alle attese. Il grafico in alto a destra mostra invece i risultati dell’analisi diagnostica del test considerato. Sono rappresentati due indici di affidabilità delle domande (REL.12: split-half; REL.CO: composite reliability) e tre indici di capacità predittiva del Modello di Rasch (ACC: accuracy; SEN: sensibility; SPE: specificity). I valori ottenuti tutti elevati (il massimo è 100%) indicano una adeguata coerenza dei quesiti e una buona capacità predittiva del test.
Il programma pluriennale di verifica dei livelli di competenze linguistiche definito per la Provincia di Trento da IPRASE con il TLT troverà la sua conclusione con la terza rilevazione, che sarà effettuata nella primavera del 2020: negli ultimi mesi di quest’anno è in corso la definizione del nuovo campione di istituti-classi e gli esperti linguistici insieme al team di docenti sono già al lavoro per predisporre la nuova versione dei test standardizzati.
Riferimento bibliografico
Carpita M., Chicco M., Covi L., Oliviero M. (2018). L’Esperienza TLT 2018: usare la statistica per accertare le competenze linguistiche degli studenti trentini. Induzioni: demografia, probabilità, statistica a scuola, 57(2). DOI: 10.19272/201800902001.