Vito M. R. Muggeo, Mariano Porcu, Gianluca Sottile
L’ultimo dPCM emanato dal governo nazionale in vigore dal 6/11/2020 ha stabilito una classificazione delle regioni italiane in tre categorie che definiscono l’estensione dei provvedimenti di distanziamento sociale. Queste tre categorie sono state poi contrassegnate, in maniera evocativa del livello di gravità dell’epidemia, coi colori giallo, arancione e rosso, sulla base dei valori assunti da una batteria di 21 indicatori che rappresenta il “coefficiente di rischio” per i territori. Come riportato dagli organi di informazione questi 21 indicatori si basano sui dati che il Dipartimento della Protezione Civile diffonde quotidianamente (nuovi casi, numero di tamponi effettuati, numero di ricoveri, ecc.) e su altre informazioni trasmesse al Ministero della Salute dalle regioni.
Nell’attesa che venga resa disponibile la base di dati sulla quale (pensiamo) si cimenteranno tutti gli statistici per proporre i loro modelli e le loro analisi, abbiamo pensato di presentare un semplice criterio che sfrutti e ottimizzi il contenuto informativo dei dati già forniti dalla Protezione Civile Nazionale.
Il nostro punto di partenza è rappresentato dai seguenti indicatori definiti in modo che a valori più elevati corrisponda una maggiore gravità della diffusione:
- Tasso di crescita o trasmissibilità della malattia, ovvero indice di Riproduzione Rt; stimato sul numero di nuovi casi positivi (NC);
- Tasso di crescita sul numero di nuovi casi positivi rapportato al numero di tamponi processati (NCagg);
- Tasso di crescita del numero degli ospedalizzati(RIC);
- Tasso di crescita dei posti in terapia intensiva (TI);
- Nuovi casi positivi rapportato al totale dei casi testati (NC/CTest);
- Attività di screening, espressa come % di casi non testati sulla popolazione residente (CTest/Pop);
- Nuovi casi positivi da sospetto diagnostico sul totale di nuovi casi positivi (NCSD/NC);
- Livello di sofferenza dei reparti di terapia intensiva, ovvero differenza tra il numero dei posti di terapia intensiva occupati e la soglia critica fissata dal Ministero della Salute (decreto del 30/4/2020) nel 30% dei posti disponibili (soffTI30%);
- % di persone in isolamento domiciliare sul totale della popolazione regionale (isol/Pop);
- numero di decessi sul totale della popolazione regionale (Dec/Pop).
La (co)variabilità complessiva dei 10 indicatori può essere rappresentata dal correlation plot rappresentato nella Figura 1, ovvero i coefficienti di correlazione tra tutte le diverse coppie degli indicatori sopra descritti.
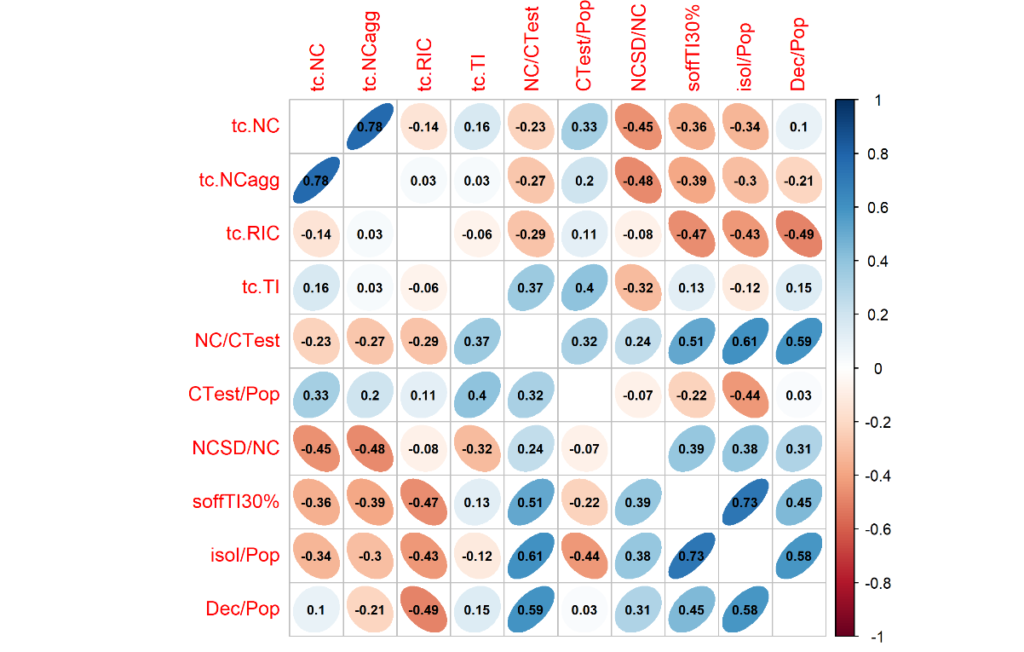 |
| Figura 1. Correlation plot per i 10 indicatori ricavati dai dati della Protezione Civile per le 21 regioni italiane, nel periodo 5-11 novembre 2020 Per ogni coppia di indicatori, la forma ed il colore di ogni ellisse dipende dal valore del coefficiente di correlazione sovrascritto |
Applicheremo l’Analisi delle Componenti Principali (ACP) per sfruttare l’intero contenuto informativo dei 10 indicatori, ridurre le ridondanze e ottenere un numero ridotto di “nuovi” indicatori (le Componenti Principali, CP) espressivi del livello di gravità della pandemia. Tuttavia, utilizzando l’approccio usuale attraverso i soli coefficienti di correlazione per definire l’indicatore di sintesi (cioè le CP), si rischia di non sfruttare appieno l’informazione della variabilità dei singoli indicatori. Ad esempio, se tra gli indicatori iniziali ve ne fosse uno non correlato con gli altri, questo non avrebbe alcun ruolo nella determinazione delle CP, a prescindere da quanto i suoi valori possano essere diversi tra le regioni. Per ovviare a questo limite considereremo oltre che il grado di ridondanza (ovvero le correlazioni) tra gli indicatori originari, anche le informazioni sulla variabilità di ogni indicatore[1].
Applicando questo approccio alternativo alla ACP standard è stato possibile definire due nuovi indicatori di sintesi che da soli sono in grado di rappresentare oltre il 95% della variabilità complessiva che si osserva tra i valori degli indicatori originari nelle varie regioni. Come termine di raffronto, se avessimo applicato una ACP standard agli stessi dati (vale a dire utilizzando solo i coefficienti di correlazione) le prime due componenti principali ottenute avrebbero spiegato poco più del 58% della variabilità totale.
Le componenti principali ottenute per il periodo 5-11 novembre sono
CP1 = 0.978 tc.NCagg + 0.198 tc.NC – 0.06 soffTI30%
CP2 = 0.944 soffTI30% + 0.258 Dec/Pop+0.120 isol/Pop+ 0.084 NC/CTest + 0.019 tc.TI
+0.057 tc.NCagg +0.048 NCSD/NC -0.081 tc.RIC
dove i pesi relativi agli altri indicatori iniziali non sono stati esplicitati perché prossimi allo zero. Le variabili riportate nelle formule non sono espresse sulla loro scala di misura originaria ma in punteggi standardizzati[2]. Per come sono stati definiti gli indicatori elementari, è chiaro che un livello più elevato di gravità dell’epidemia è espresso da valori elevati in entrambe le CP.
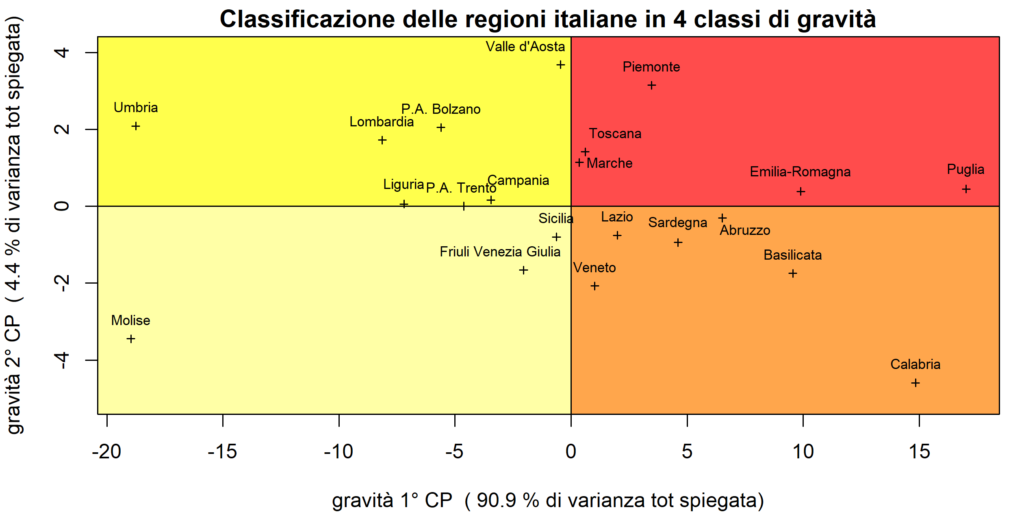
Cerchiamo ora di “interpretare” le componenti: la prima componente può essere considerata come un gradiente della velocità di diffusione della epidemia, espressa dal tasso di crescita (o equivalentemente dall’indice Rt), soprattutto quando si tiene conto anche del numero dei tamponi processati. Il segno del coefficiente di soffTI30% è contro-intuitivo rispetto a questa interpretazione ma il suo valore è piccolo e, sostanzialmente, trascurabile. La seconda componente rappresenta l’impatto del COVID-19 sulle strutture sanitarie ed è legata, prevalentemente, ai valori espressi dagli indicatori soffTI30% e Dec/Pop (e in misura minore da alcuni altri indicatori). Anche per la seconda componente c’è un coefficiente che è negativo ma, anche in questo caso, in pratica irrilevante. I valori delle CP calcolate in ogni regione secondo le formule riportate, consentono di avere due sole misure della gravità dell’epidemia che da sole spiegano la maggior parte delle informazioni sulla variabilità contenute nei 10 indicatori iniziali. Questa coppia di valori può essere impiegata per definire una semplice classificazione delle regioni, come riportato nella Figura 2 in alto per il periodo 5-11 novembre. Ripetendo la stessa analisi per il periodo 20-26 novembre, si ottengono i risultati riportati nella figura di sotto. I coefficienti delle nuove componenti non sono riportati per brevità.
La Figura 2 mostra porzioni di spazio che delimitano i 4 gruppi di regioni con valori delle due CP superiori od inferiori alla media.
 |
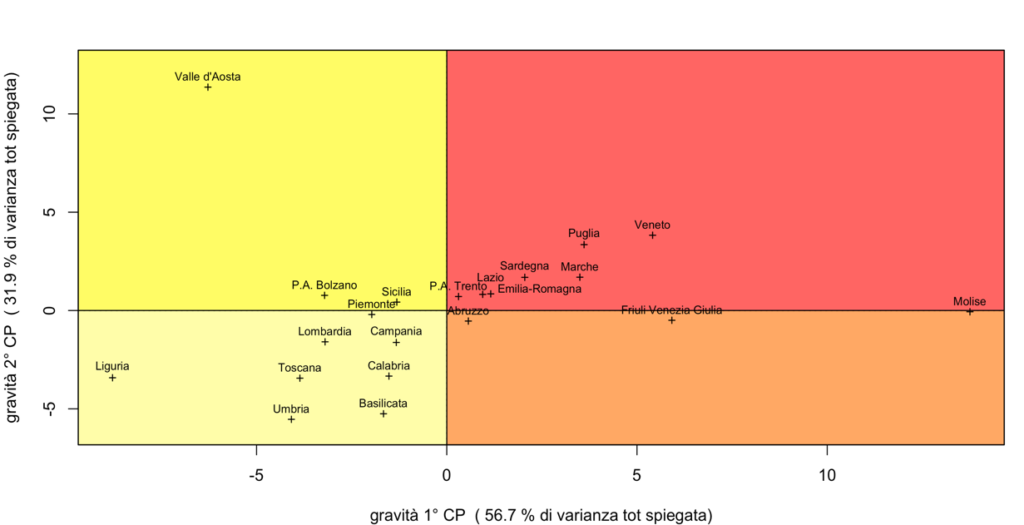 |
| Figura 2. Classificazione delle regioni in 4 aeree di rischio secondo le prime 2 CP utilizzando gli indicatori elaborati sulla base dei dati diffusi dal DPC nel periodo dal 5 al 11 novembre 2020 (figura in alto) e 20 al 26 novembre 2020 (figura in basso). |
La Figura 2 non propone una classificazione alternativa a quella ufficiale (ricordiamo che i risultati non considerano i dati non disponibili sulla solidità delle strutture ospedaliere), ma vuole essere un semplice esempio di come le informazioni già disponibili e utilizzate per monitorare specifici aspetti della pandemia, possano essere ulteriormente elaborate per definire una classificazione trasparente e riproducibile. Come riportato da più parti[3], la divisione in zone di rischio ha spesso alimentato lo scontento, soprattutto da parte degli enti locali, e per questa ragione è auspicabile che le restrizioni a livello regionale vengano adottate sulla base di criteri oggettivi e condivisi e, soprattutto, di dati verificabili e accessibili.
[1] Per una discussione sulla ACP attraverso l’utilizzo simultaneo di correlazioni e variabilità si veda https://www.researchgate.net/publication/345598894.
[2] I punteggi standardizzati impiegati sono del tipo (X-media)/|media|, diversi da quelli usuali (X-media)/dev.st
[3] Ad esempio, si veda https://rep.repubblica.it/pwa/commento/2020/11/10/news/la_classifica_delle_regioni_quando_i_colori_impazziscono-273897909/
https://www.repubblica.it/politica/2020/11/17/news/coronavirus_conferenza_regioni_su_emergenza_covid-274689969/?ref=RHTP-BH-I274589166-P1-S2-T1